A Pluggable XML Editor
May 31, 2012

Ever since I announced my HTML5-based XML editor, I've been getting all sorts of requests for a variety of implementations. While the focus has been, and continues to be, providing an Akoma Ntoso based legislative editor, I've realized that the interest in a web-based XML editor extends well beyond Akoma Ntoso and even legislative editors.
So... with that in mind I've started making some serious architectural changes to the base editor. From the get-go, my intent had been for the editor to be "pluggable" although I hadn't totally thought it through. By "pluggable" I mean capable of allowing different information models to be used. I'm actually taking the model a bit further to allow modules to be built that can provide optional functionality to the base editor. What this means is that if you have a different document information model, and it is capable of being round-tripped in some way with an editing view, then I can probably adapt it to the editor.
Let's talk about the round-tripping problem for a moment. In the other XML editors I have worked with, the XML model has had to quite closely match the editing view that one works with. So you're literally authoring the document using that information model. Think about HTML (or XHTML for an XML perspective). The arrangement of the tags pretty much exactly represents how you think of an deal with the components of the document. Paragraphs, headings, tables, images, etc, are all pretty much laid out how you would author them. This is the ideal situation as it makes building the editor quite straight-forward.
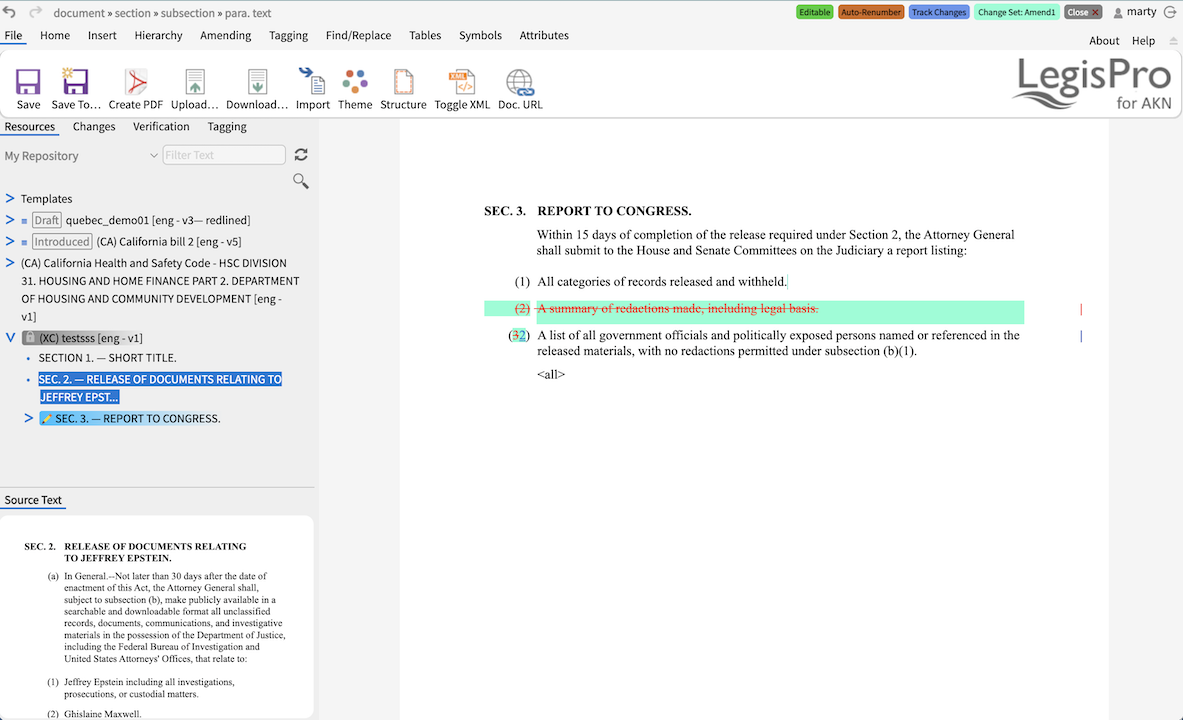
However, this isn't always the case. Depending on how much this isn't the case determines how feasible building an editor is at all. Sometimes the issues are minor. For instance, in Akoma Ntoso, a section "num" element is out-of-line with the content block containing the paragraphs. So while it is quite common for the num to be inline in the first paragraph of the the section, that isn't how Akoma Ntoso chooses to represent this. And it gets more difficult from there when you start dealing with subsections and sub-subsections.
To deal with these sorts of issues, a means of translating back and forth between what you're editing and the information model you're building is needed. I am using XSL Transforms, designed specifically for round-tripping to solve the problem. Not every XML model lends itself to document authoring, but by building a pluggable translating layer I'm able to adapt to more models than I have been able to in the past.
Along with these mechanisms I am also allowing for pluggable command structures, CSS styling rules, and, of course, the schema validation. In fact, the latest release of the editor at legalhacks.org has been refactored and now somewhat follows this pluggable architecture.
Next I plan to start working with modules like change tracking / redlining, metadata generation (including XBRL generation), and multilingual support following this pluggable architecture. I'm totally amazed at how much more capable HTML5 is turning out to be when compared to old-fashioned HTML4. I can finally build the XML editor I always wanted.



.png)